[ad_1]
Let’s say you need to measure the connection between a number of variables. One of many best methods to do that is with a linear regression (e.g., abnormal least squares). Nevertheless, this technique assumes that the connection between all variables is linear. One might additionally use generalized linear fashions (GLM) through which variables are reworked, however once more the connection between the end result and the reworked variable is–you guessed it–linear. What for those who needed to mannequin the next relationship:

On this information, each variables are usually distributed with imply of 0 and normal deviation of 1. Moreover, the connection is essentially co-monotonic (i.e., because the x variable will increase so does the y). But the correlation will not be fixed; the variables are intently correlated for small values, however weakly correlated for big values.
Does this relationship truly exist in the actual world? Definitely so. In monetary markets, returns for 2 totally different shares could also be weakly constructive associated when shares or going up; nonetheless, throughout a monetary crash (e.g., COVID, dot-com bubble, mortgage disaster), all shares go down and thus the correlation could be very robust. Thus, having the dependence of various variables fluctuate by the values of a given variable is extremely helpful.
How might you mannequin this kind of dependence? A nice collection of movies by Kiran Karra explains how one can use copulas to estimate these extra advanced relationships. Largely, copulas are constructed utilizing Sklar’s theorem.
Sklar’s theorem states that any multivariate joint distribution could be written when it comes to univariate marginal distribution features and a copula which describes the dependence construction between the variables.
https://en.wikipedia.org/wiki/Copula_(probability_theory)
Copulas are fashionable in high-dimensional statistical functions as they permit one to simply mannequin and estimate the distribution of random vectors by estimating marginals and copulae individually.
Every variable of curiosity is reworked right into a variable with uniform distribution starting from 0 to 1. Within the Karra movies, the variables of curiosity are x and y and the uniform distributions are u and v. With Sklar’s theorem, you’ll be able to remodel these uniform distributions into any distribution of curiosity utilizing an inverse cumulative density operate (which are the features F-inverse and G-inverse respectively.
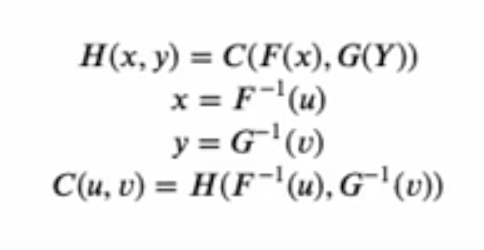
In essence, the 0 to 1 variables (u,v) serve to rank the values (i.e., percentiles). So if u=0.1, this provides the tenth percentile worth; if u=0.25, this provides the twenty fifth percentile worth. What the inverse CDF features do is say, for those who say u=0.25, the inverse CDF operate gives you the anticipated worth for x on the twenty fifth percentile. In brief, whereas the mathematics appears difficult, we’re actually simply in a position to make use of the marginal distributions based mostly on 0,1 ranked values. Extra info on the mathematics behind copulas is beneath.
The subsequent query is, how can we estimate copulas with information? There are two key steps for doing this. First, one wants to find out which copula to make use of, and second one should discover the parameter of the copula which most closely fits the information. Copulas in essence intention to search out the underlying relies upon construction–the place dependence relies on ranks–and the marginal distributions of the person variables.
To do that, you first remodel the variables of curiosity into ranks (mainly, altering x,y into u,v within the instance above). Beneath is a straightforward instance the place steady variables are reworked into rank variables. To crease the u,v variables, one merely divides by the utmost rank + 1 to insure values are strictly between 0 and 1.

As soon as now we have the rank, we will estimate the connection utilizing Kendall’s Tau (aka Kendall’s rank correlation coefficient). Why would we need to use Kendall’s Tau somewhat than a daily correlation? The reason being, Kendall’s Tau measure the connection between ranks. Thus, Kendall’s Tau is similar for the unique and ranked information (or conversely, similar for any inverse CDF used for the marginals conditional on a relationship between u and v). Conversely, the Pearson correlation could fluctuate between the unique and ranked information.
Then one can decide a copulas type. Widespread copulas embody the Gaussian, Clayton, Gumbel and Frank copulas.
The instance above was for 2 variables however one energy of copulas is that can be utilized with a number of variables. Calculating joint chance distributions for numerous variables is usually difficult. Thus, one method to attending to statistical inference with a number of variables is to make use of vine copulas. Vine copulas depend on chains (or vines) or conditional marginal distributions. In brief, one estimat
As an example, within the 3 variable instance beneath, one estimates the joint distributions of variable 1 and variable 3; the joint distribution of variable 2 and variable 3 after which one can estimate the distribution of variable 1 conditional on variable 3 with variable 2 conditional on variable 3. Whereas this appears advanced, in essence, we’re doing a collection of pairwise joint distributions somewhat than making an attempt to estimate joint distributions based mostly on 3 (or extra) variables concurrently.
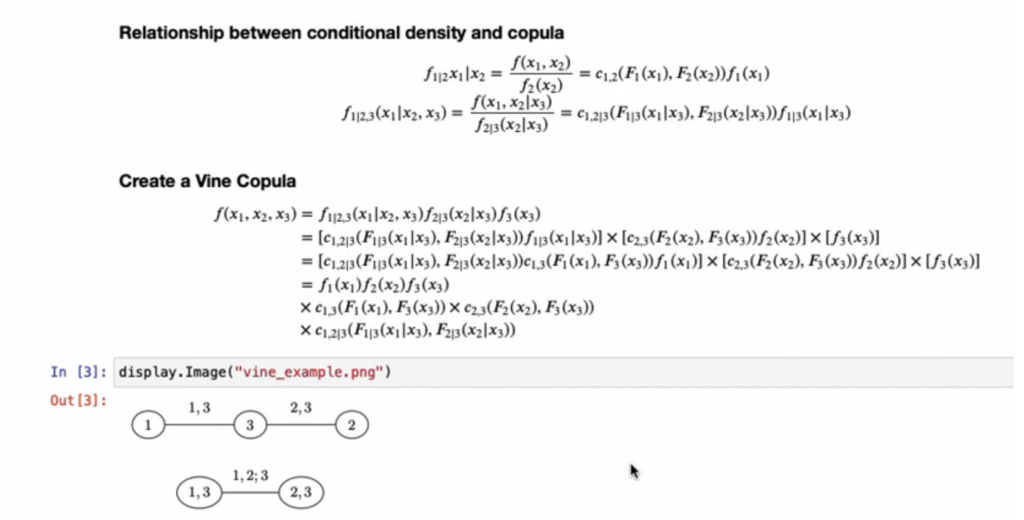
The video beneath describes vine copulas and the way they can be utilized for estimating relationships for greater than 2 variables utilizing copulas.
For extra element, I like to recommend watching the complete collection of movies.
[ad_2]